Biography
I am a final-year undergraduate in Mathematics and Applied Mathematics (National Science Base Class) at Xinjiang University (XJU) (新疆大学), graduating with a top 3% GPA and the university-level Outstanding Graduate distinction. I have been admitted, via direct recommendation, to the School of Mathematics and Statistics at Xi'an Jiaotong University (XJTU) (西安交通大学) for an M.S. in Applied Mathematics. My research interests center on World Models, Reinforcement Learning, Diffusion Models, and Vision-Language-Action (VLA).
I first worked as a Reinforcement Learning Algorithm Intern at the Institute of Automation, Chinese Academy of Sciences (CASIA) (中科院自动化所) in the Complex Systems Cognition and Decision Laboratory, where I focused on multi-agent reinforcement learning, world-model navigation, and embodied intelligence. I then joined Meituan(美团)'s Autonomous Vehicle Business Unit as an Autonomous Driving Algorithm Intern in the Motion Planning and Control group, working on multimodal trajectory generation with Flow Matching, Energy Field modeling, and reinforcement learning. I am now an Embodied AI Algorithm Intern at LinkerBot (灵心巧手) Evo Lab, working on World Action Model (WAM) transfer, post-training, and real-machine deployment for robotic arms with multi-DoF dexterous hands. My long-term goal is to build generalizable and practical learning and planning methods for real-world intelligent systems.
I am open to collaboration — feel free to reach me by e-mail.
News
- [2026/01/06] Our paper 'Spatial Sampling-based Passivity and Synchronization of Multiweighted Coupled Reaction-diffusion Neural Networks' has been accepted by CNSNS.
- [2025/09/01] Our paper 'Adaptive Passivity-based Synchronization of Spatiotemporal Neural Networks with Multi-weighted Coupling under Spatially Point Measurements' has been accepted by CISC 2025.
Selected Publications
-
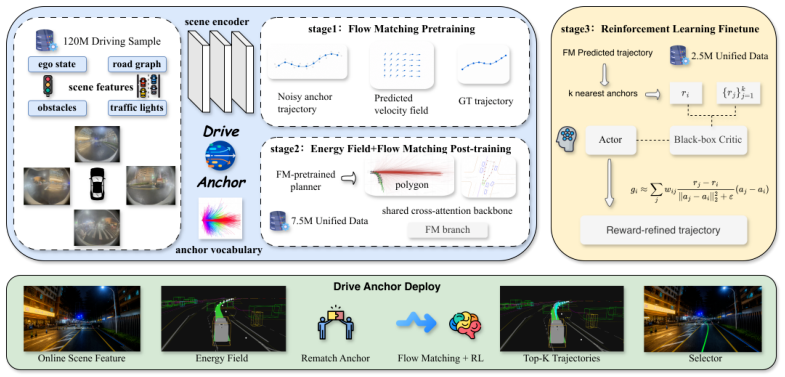
DriveAnchor: Progressive Anchor-based Flow Learning for Autonomous Driving Planning
Limin Yan*†, Haoyun Tang*, Yutao Qiu, Hongqing Liu, Haoyu Xu‡ * Equal contribution. † Lead corresponding author. ‡ Co-corresponding author. arXiv:2606.00519, 2026 [arXiv] -
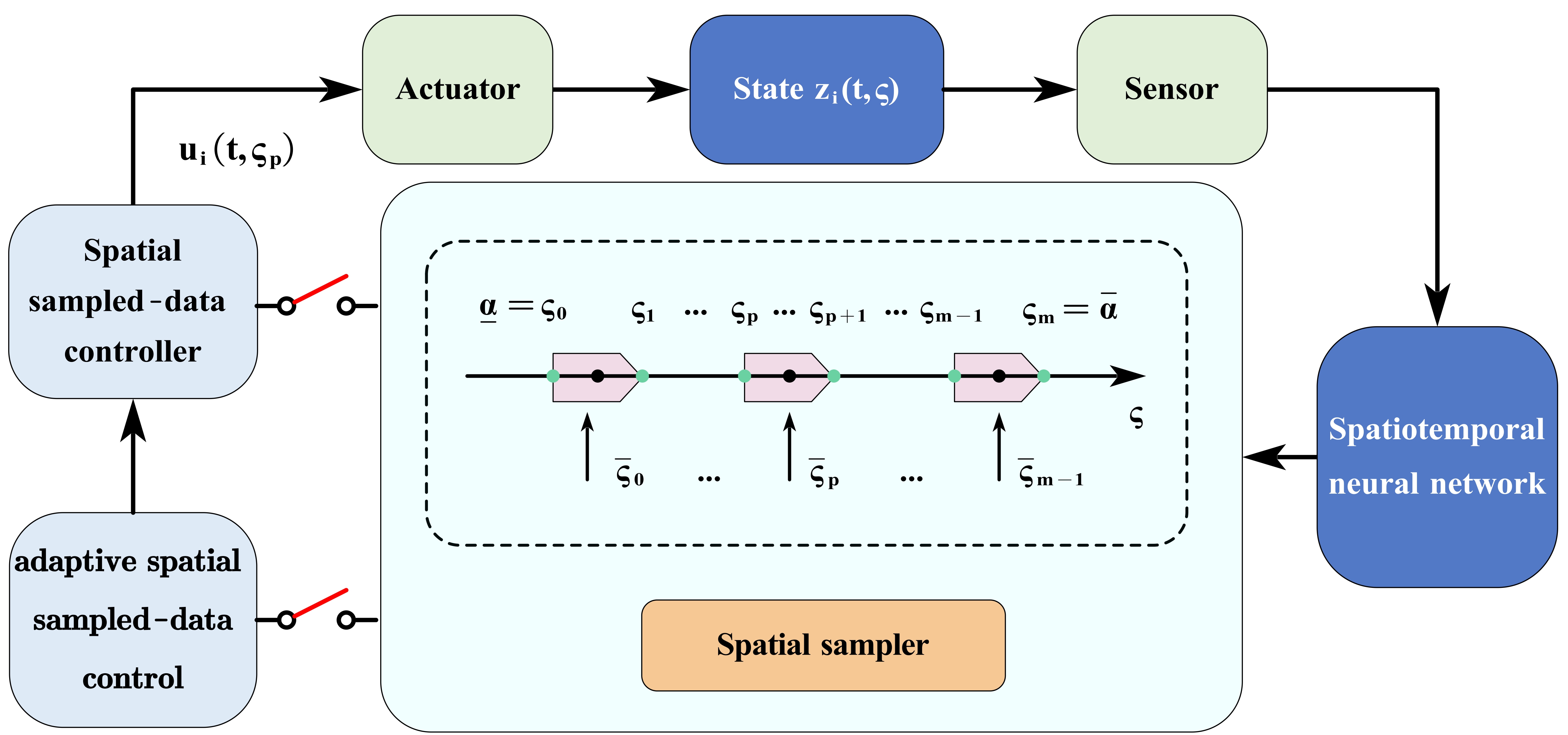
Spatial Sampling-based Passivity and Synchronization of Multiweighted Coupled Reaction-diffusion Neural Networks
Haodong Cui, Haoyun Tang, Mingyu Ma, Cheng Hu†, Tingting Shi † Corresponding author. Communications in Nonlinear Science and Numerical Simulation (CNSNS, 中科院一区), 2025 [PDF] -
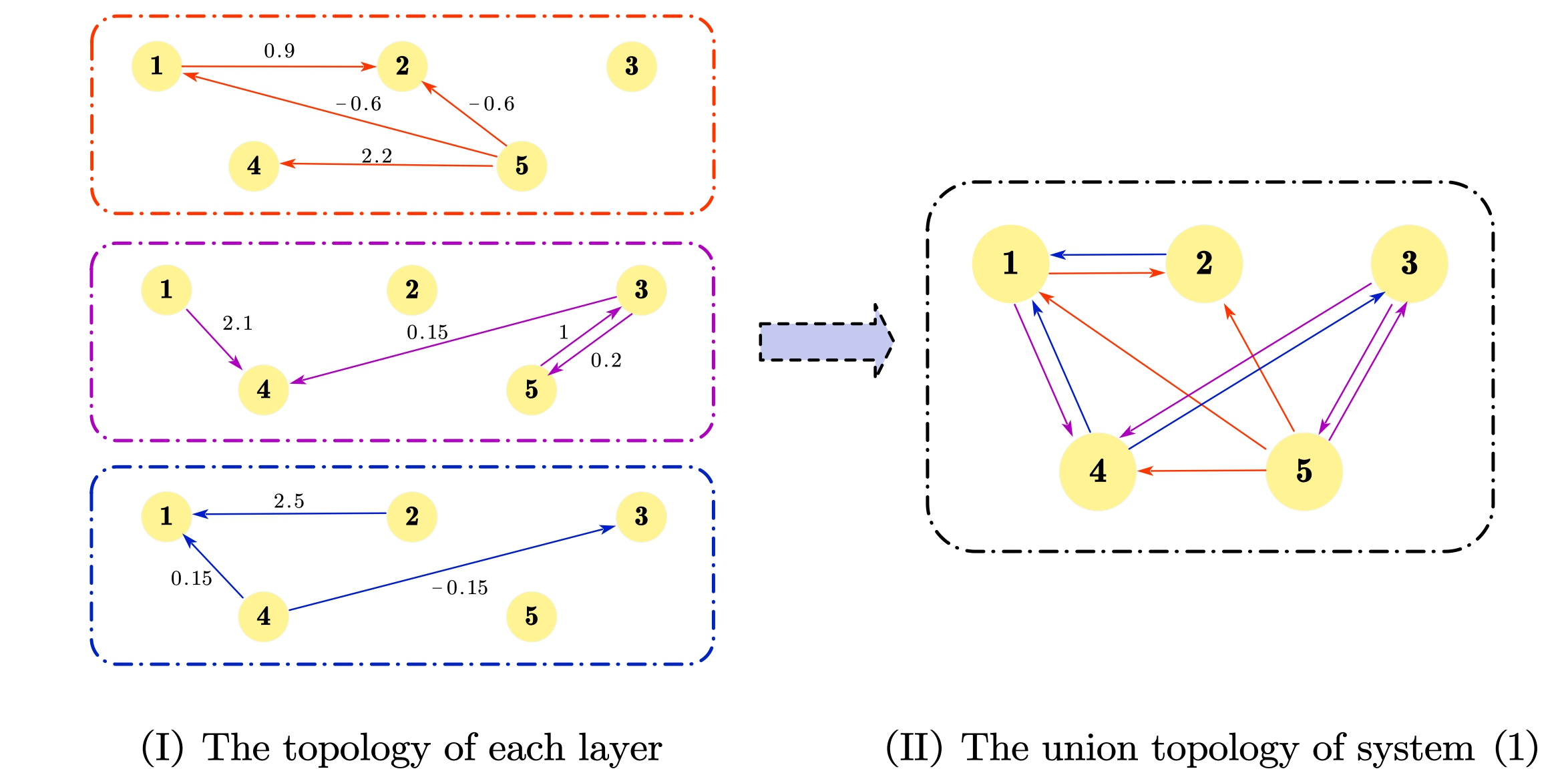
Adaptive Passivity-based Synchronization of Spatiotemporal Neural Networks with Multi-weighted Coupling under Spatially Point Measurements
Haoyun Tang, Haodong Cui, Mingyu Ma, Cheng Hu†, Tingting Shi † Corresponding author. Chinese Intelligent Systems Conference, 2025 [PDF]
Education


Research & Industry Experience



Selected Awards & Honors
- Meritorious Winner, MCM (美国大学生数学建模竞赛 M 奖), 2025 [PDF]
- Provincial Special Prize, CUMCM (全国大学生数学建模竞赛省级特等奖), 2023
- Provincial First Prize, National Mathematical Competition (全国大学生数学竞赛 A 类省级一等奖), 2024
- Provincial Second Prize, Market Research Competition (全国市场研究与分析大赛省级二等奖), 2024
- Provincial Second Prize, Statistical Modeling Competition (全国大学生统计建模大赛省级二等奖), 2024
- National Second Prize, APMCM (亚太地区大学生数学建模竞赛国家二等奖), 2024
- National Third Prize, HuaShu Cup (华数杯全国大学生数学建模竞赛国家三等奖), 2024
- Jinlongyu Academic Scholarship (金龙鱼学业奖学金), 2025
Selected Projects
-

Car Obstacle Avoidance Navigation (DreamV3) [Demo] Keywords: DreamV3, Autonomous Navigation, Obstacle Avoidance, Reinforcement Learning Built a small-car navigation project using DreamV3-style world model reinforcement learning for obstacle avoidance and autonomous route following in a structured driving environment.
-

UAV Obstacle Avoidance Navigation (SAC) [Demo] Keywords: UAV, SAC, Obstacle Avoidance, Reinforcement Learning Built a UAV obstacle avoidance navigation experiment using Soft Actor-Critic to learn collision-aware flight behavior in a structured simulation environment.
-

Road2Gen-Drive (MetaDrive IL+RL / GAIL) [GitHub] Keywords: MetaDrive, Behavior Cloning, PPO, GAIL, Generalization Built end-to-end autonomous driving experiments in MetaDrive with two independent pipelines: IL+RL (BC pretraining + PPO fine-tuning) and GAIL for adversarial imitation learning and generalization evaluation.
-

Multi-UAV Collaborative Surrounding (MAPPO + AirSim) [GitHub] Keywords: AirSim, MAPPO, Multi-UAV, Curriculum Learning Built a 3v1 multi-UAV cooperative surrounding environment in AirSim and a MAPPO training pipeline with curriculum learning and tailored reward design.
Hobbies & Interests
Outside research, I enjoy suspense and science-fiction films. I also play basketball as a starting power forward, with two college tournament championships, and keep active through running, badminton, swimming, and hiking.